


Créer son ChatGPT à la maison
- Installer un LLM
- Charger un modèle IA
- Installer Open WEBUI
- Configurer Open WEBUI
- Have a fun !
Installer un LLM
Installation d’Ollama du groupe Méta
Les prérequis pour un utilisateur sont 4 VCPU minimum. Il faut pour faire tourner de petits modèles (7 Billions de paramètres) 16 Go de RAM. Pour l’espace disque tout dépendra du nombre de modèles chargé, mais 30 Go me semble un minimum tout compris.
Pour installer Ollama, il n’y a rien de plus simple tout se fait en une commande avec le script d’installation officiel.
sudo apt install python3 python3-pip git
curl -fsSL https://ollama.com/install.sh | sh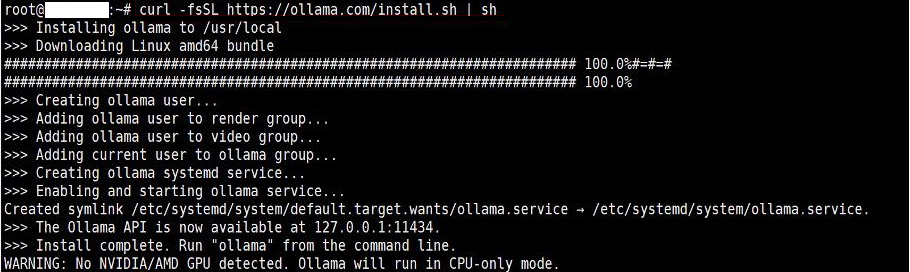
Le WARNING est normal dans un environnement virtuel sans pont vers le hardware. Pour lever cette contrainte, il faudra configurer proxmox spécifiquement pour le conteneur si toute fois la machine hôte comprend une carte Nvidia.
Vérifions que tout fonctionne en affichant la version installée.
ollama --version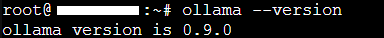
Maintenant, vérifiions que le service Linux fonctionne.
service ollama status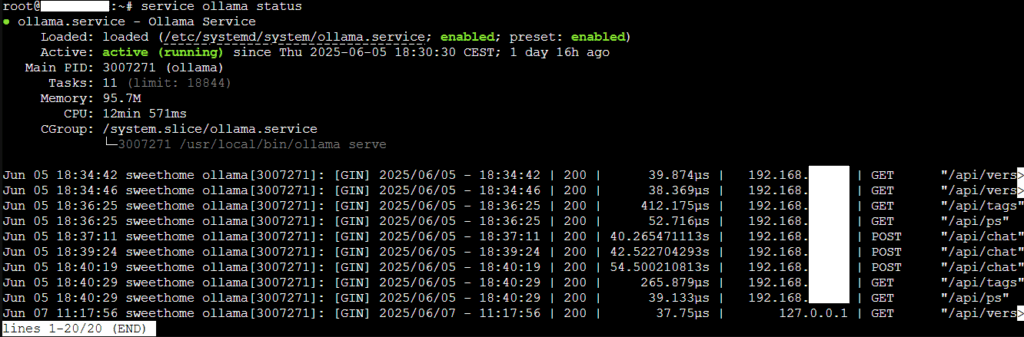
Si vous souhaitez exécuter Open WEBUI sur la même instance, vous pouvez ignorer cette section.
Nous allons changer l’adresse d’écoute de Ollama pour la faire écouter sur toutes les adresses (0.0.0.0) ou une adresse spécifique.
On modifie le service Linux pour la prise en compte d’une nouvelle variable d’environnement.
sudo vi /etc/systemd/system/ollama.serviceDans la section service, ajoute la ligne OLLAMA_HOST,
[Service] Environment="OLLAMA_HOST=0.0.0.0:11434"
On redémarre le service pour une prise en compte
sudo systemctl daemon-reload
sudo systemctl restart ollamaOn vérifie que la prise en compte est faite, avec la commande suivante :
ss -tupln
S’il la commande indique une étoile alors l’écoute se fait pour toutes les adresses IP (Attention IPV6 par défaut). Au cas où il faut écouter sur les deux protocoles, il faut activer le forwarding au niveau TCP/IP.
Activons le forwarding TCP/IP pour tous les protocoles TCP dans le fichier de configuration sysctl.conf.
vim /etc/sysctl.confAjoutez où décommentez les lignes suivantes :
net.ipv4.ip_forward = 1net.ipv6.conf.all.forwarding = 1
Pour appliquer les changements immédiatement
sudo sysctl -pInstallation d’un modèle Hugging face
Il existe une multitude de modèles sur Hugging face. Pour le Lab, nous installerons le modèle Llama3.2 car il est peu gourmand en ressources.
ollama pull Llama3.2On teste que tout fonctionne depuis l’invite de commande shell.
ollama run Llama3.2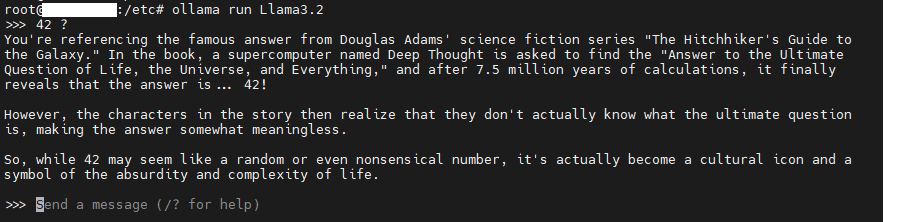
Par défaut, le chemin de stockage des modèles est :
- macOS :
~/.ollama/models - Linux :
/usr/share/ollama/.ollama/models - Windows :
C:\Users\%username%\.ollama\models
Il faut s’assure que ces répertoires dispose de suffisamment d’espace sur le FS / partition.
Le chemin peut être modifié avec la variable d’environnement OLLAMA_MODELS du fichier ollama.service comme décrit plus pour l’adresse IP.
Environment="OLLAMA_MODELS=/new/path/to/models"
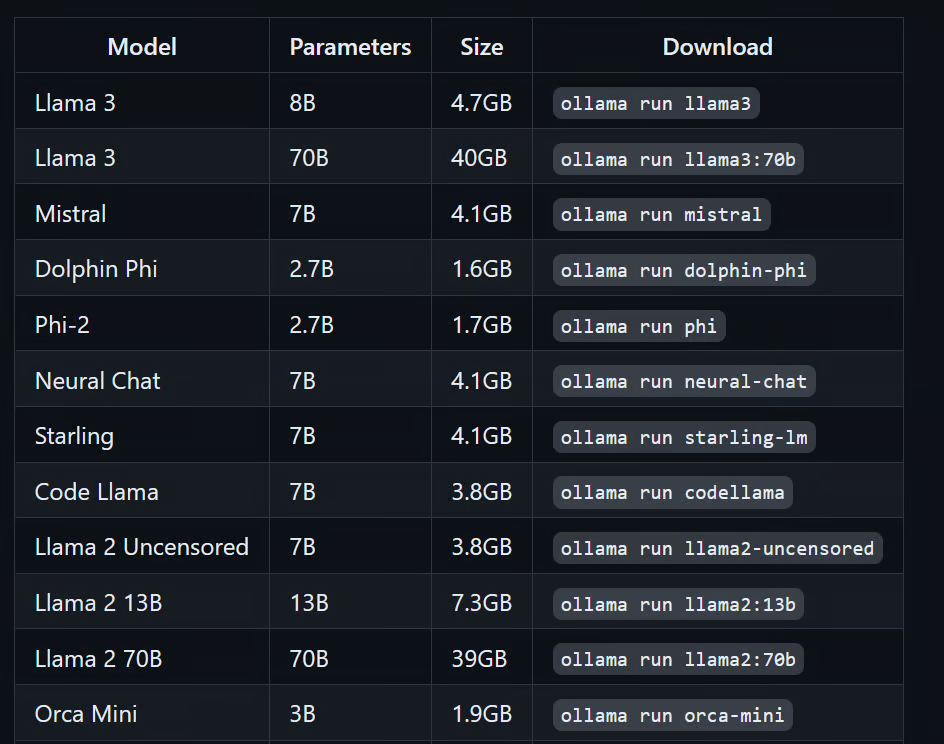
Voici quelques exemples de modèle et de commande ollama.
Installation d’Open WEBUI
Les prérequis techniques sont une version de python 3.x, le gestionnaire pip et un client git.
sudo apt install python3 python3-pip gitInstallation d’Open WEBUI et met à jour avec la dernière version disponible.
pip install open-webui
python -m pip install --upgrade pip
open-webui serve